js 引擎
| 浏览器 | JavaScript 引擎 |
|---|---|
| chrome | V8 |
| safari | JavaScriptCore |
| Firefox | SpiderMonkey |
| Edge | Chakra |
js 执行过程
- 对源码进行词法分析
- 进行语法分析
- 生成抽象语法树
- 生成可执行代码(可能有优化过程,此处代码可能是字节码或者机器码)
- 执行
词法分析
将程序源代码分解成对编程语言来说有意义的代码块,这些代码块被称为词法单元(token)。
语法分析
根据生成的 Token 进行语法分析。
V8 引擎
主要模块
Parser
负责将 JavaScript 源码转换为 Abstract Syntax Tree (AST)。在 V8 中有两个解析器用于解析 JavaScript 代码,分别是 Parser 和 Pre-Parser 。
Parser解析器又称为full parser(全量解析) 或者eager parser(饥饿解析)。它会解析所有立即执行的代码,包括语法检查,生成AST,以及确定词法作用域。Pre-Parser又称为惰性解析,它只解析未被立即执行的代码(如函数),不生成AST,只确定作用域,以此来提高性能。当预解析后的代码开始执行时,才进行Parser解析。
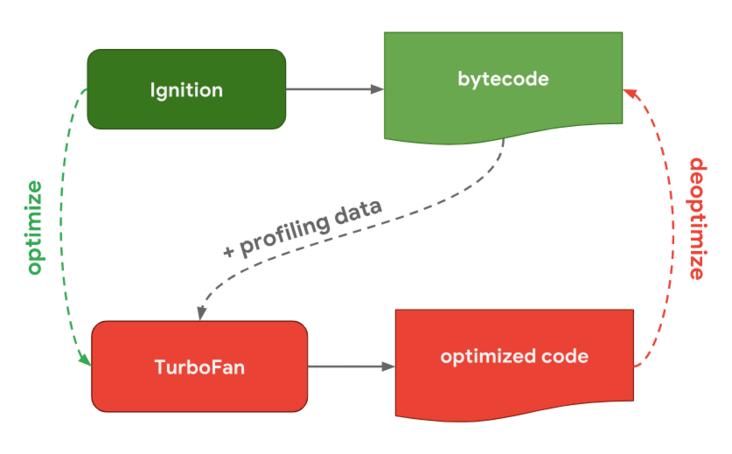
Ignition
interpreter,即解释器,负责将 AST 转换为 Bytecode,解释执行 Bytecode;同时收集 TurboFan 优化编译所需的信息,比如函数参数的类型
TurboFan
compiler,即编译器,利用 Ignitio 所收集的类型信息,将 Bytecode 转换为优化的机器代码
Orinoco
garbage collector,垃圾回收模块,负责将程序不再需要的内存空间回收;
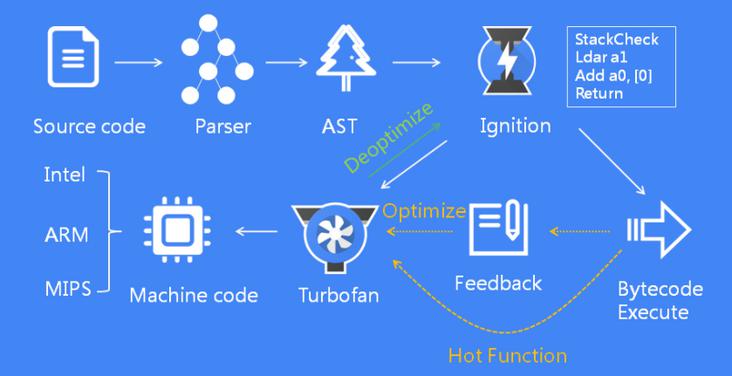
执行过程
- 扫描所有的源代码,进行词法分析,生成
Tokens Parser解析器根据Tokens生成AST,存在预编译和编译Ignition解释器将AST转换为字节码,并解释执行TurboFan编译器负责将热点函数优化编译为机器指令执行
优化及优化导致的问题修复
当 Ignition 开始执行 JavaScript 代码后,V8 会一直观察 JavaScript 代码的执行情况,并记录执行信息,如每个函数的执行次数、每次调用函数时,传递的参数类型等。
如果一个函数被调用的次数超过了内设的阈值,监视器就会将当前函数标记为热点函数(Hot Function),并将该函数的字节码以及执行的相关信息发送给 TurboFan。TurboFan 会根据执行信息做出一些进一步优化此代码的假设,在假设的基础上将字节码编译为优化的机器代码。如果假设成立,那么当下一次调用该函数时,就会执行优化编译后的机器代码,以提高代码的执行性能;如果假设不成立,不知道你们有没有注意到上图中有一条由 optimized code 指向 bytecode 的红色指向线。此过程叫做 deoptimize(优化回退),将优化编译后的机器代码还原为字节码。