事件循环
由于 JS 是单线程非阻塞的,所有的任务都需要在这个线程中来处理。当需要执行异步任务时主线程会先挂起这个任务,当异步任务执行完毕之后主线程会根据规则执行回调。当任务处理完毕之后, JS 会将这个事件加入队列中,这个队列即被称为事件队列。
进程和线程
- 进程:
CPU在运行指令及加载和保存上下文所需的时间,放在应用上来说就代表了一个程序。 - 线程: 进程中的更小单位,描述了执行一段指令所需的时间。
在浏览器中,当你打开一个 Tab 页时,其实就是创建了一个进程,一个进程中可以有多个线程,比如渲染线程、JS 引擎线程、HTTP 请求线程等等。当你发起一个请求时,其实就是创建了一个线程,当请求结束后,该线程可能就会被销毁。
在 JS 运行的时候会阻止 UI 渲染,这是因为 JS 可以修改 DOM,如果在 JS 执行的时候 UI 线程还在工作,就可能导致不能安全的渲染 UI。这其实也是一个单线程的好处,得益于 JS 是单线程运行的,可以达到节省内存,节约上下文切换时间,没有锁的问题的好处。
对于锁的问题,形象的来说就是当我读取一个数字 15 的时候,同时有两个操作对数字进行了加减,这时候结果就出现了错误。解决这个问题也不难,只需要在读取的时候加锁,直到读取完毕之前都不能进行写入操作。
执行栈
所有的 JS 代码在运行时都是在执行上下文中进行的。JS 中有三种执行上下文:
- 全局执行上下文,默认的,浏览器中是
window对象,nodejs中是global,并且this在非严格模式下指向它们。 - 函数执行上下文,
JS的函数每当被调用时会创建一个上下文。 Eval执行上下文,eval函数会产生自己的上下文。
栈是一种数据结构,具有先进后出的原则。JS 中的执行栈就具有这样的结构,当引擎第一次遇到 JS 代码时,会产生一个全局执行上下文并压入执行栈,每遇到一个函数调用,就会往栈中压入一个新的上下文。引擎执行栈顶的函数,执行完毕,弹出当前执行上下文。
微任务和宏任务
异步任务被分为两种类型,微任务和宏任务
微任务
Promise.thenMutationObserverprocess.nextTick
宏任务
script(整体代码)setTimoutsetIntervalsetImmediateMessageChannelrequestAnimationFramepostMessageI/OUI交互事件
事件循环
Event Loop(事件循环)中,每一次循环称为 tick, 每一次 tick 的任务如下:
- 执行栈选择最先进入队列的宏任务(通常是
script整体代码),如果有则执行 - 检查是否存在
Microtask,如果存在则不停的执行,直至清空microtask队列 - 更新
render(每一次事件循环,浏览器都可能会去更新渲染) - 重复以上步骤
宏任务 > 所有微任务 > 宏任务,如下图所示:
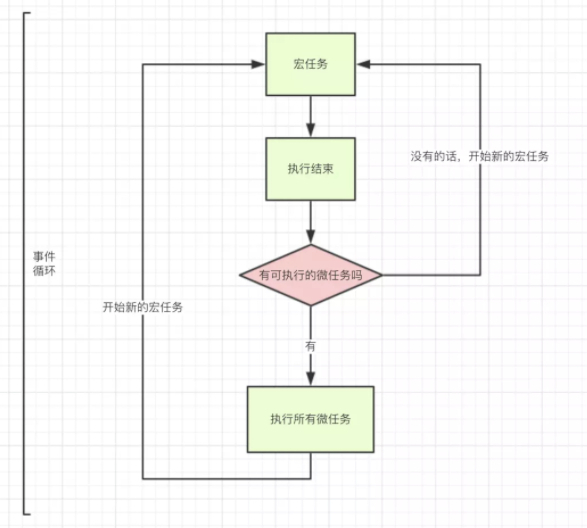
- 将所有任务看成两个队列:执行队列与事件队列。
- 执行队列是同步的,事件队列是异步的,宏任务放入事件列表,微任务放入执行队列之后,事件队列之前。
- 当执行完同步代码之后,就会执行位于执行列表之后的微任务,然后再执行事件列表中的宏任务
react 中的异步实现
react 中的异步是通过宏任务来实现的,优先使用 setImmediate ,然后使用 MessageChannel,若都不支持则使用 setTimeout 实现
1 | let schedulePerformWorkUntilDeadline |
- 判断是否存在
setImmediate,如果存在则使用setImmediate,不存在下一步 - 判断是否支持
MessageChannel,如果支持则创建一个消息通道,通过消息通道实现宏任务,否则进行下一步 - 回落到
setTimeout实现异步
说明
- 优先选择
MessageChannel而不是setTimeout的原因是由于setTimeout有一个最小4ms的等待时间,在无宏任务执行时,这个时间会浪费掉 - 不选择微任务的原因是,使用微任务的方式时,当前任务任然占据了主线程而没有释放出来,达不到把主线程还给渲染线程的目的
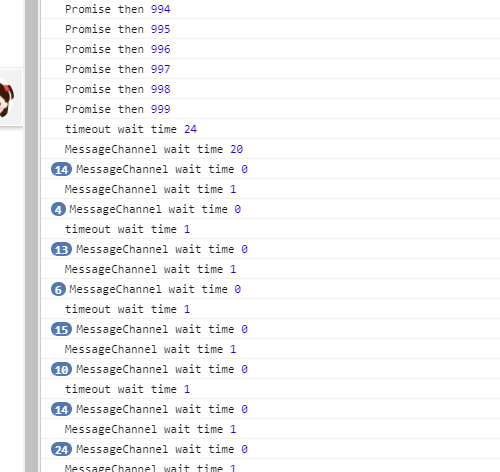
edge 浏览器测试参考